Publications¶
HGTD Tools
Annika Stein

-
Software
Gitlab: https://gitlab.cern.ch/anstein/hgtd-tools Zenodo:
2026
Abstract
Python GUI application and API client module to interact with the HGTD Production Database. Automatic reporting that syncs to eos space. Proud early adopter of zensical!
Contribution: Inventor / main developer, maintenance of software, user support, tutorials.
TopCPToolkit
ATLAS Collaboration (Annika Stein)
![]()
-
Software
Gitlab: https://gitlab.cern.ch/atlas/amg/software/TopCPToolkit
Gitlab: https://gitlab.cern.ch/atlas/amg/software/HowToExtendTopCPToolkit
Zenodo:
2026
Abstract
TopCPToolkit is an ntuple production framework for analysing data from LHC Run 2 and Run 3. It is built around common CP and analysis algorithms in release 25 of the central athena software framework of the ATLAS Collaboration.
Contribution: Development and maintenance of software, user support, tutorials as part of top reconstruction convener role, including core team coordination.
HGTD Production Database (Plots 2026)
ATLAS HGTD Project (Annika Stein)
- HGTD Public Plots
https://twiki.cern.ch/twiki/bin/view/AtlasPublic/HGTDPublicPlots#Production_Database
2026
Abstract
Results from pre-production of HGTD parts and their implementation in the Production Database along with the novel user interfaces, especially in "hgtd-tools", are presented.
Contribution: Prepared the software to upload and analyse production data for module assembly, module loading and detector assembly. Calculated / optimized the flex tail categories, setup the monitoring dashboard, reporting, gitlab CI pipeline, invented the algorithms for hybrid clustering and developed the python API client including CLI and GUI.
Novel jet flavour tagging algorithms exploiting adversarial deep learning techniques with efficient computing methods and preparation of open data for robustness studies
Annika Stein
- PhD Thesis
https://doi.org/10.18154/RWTH-2024-07840
2024
Jet Flavour Tagging OpenData Sample
Annika Stein, Taylor C. Briggs
- kaggle dataset
https://www.kaggle.com/datasets/annikastein/jet-tagging-opendata-mockup
2023
Abstract
A collection of low-level information useful for classifying a particle jet's flavour, i.e. related to the jet's constituents like charged or neutral particle flow candidates, or secondary vertex information. This is the first openly available dataset of that kind that has been derived with experiment-specific software run on top of CERN Open Data and then stored in experiment-independent format, making ROOT or similar frameworks obsolete. Get ready to jump into this fruitful particle physics task without worrying about containers, special tools and physics terminology.
Contribution: Prepared the dataset with a framework to extract and calculate low-level information based on jet constituent properties. A set of plugins and scripts have been written to facilitate the production with high-performance computing infrastructures, for experts with CMSSW experience. To facilitate exchange with other (academic) communities, I derived a novel file structure that is fully independent of experiment-specific software and which does not require any experience with ROOT. I then executed production and conversion of the samples. The file structure has been exchanged with the co-author, whose feedback was included for the public version of the dataset. I modified an exemplary notebook that shows how to use the files directly on the kaggle platform, increasing the datasets's usability score.
A first look at early 2022 proton-proton collisions at √s = 13.6 TeV for heavy-flavor jet tagging
CMS Collaboration
- Detector Performance Summary, CMS, CERN
CMS DP-2023/012
March 2023
Abstract
Identification of jets stemming from heavy-flavor (bottom or charm) hadrons relies primarily on the inputs due to reconstruction of charged particle tracks and secondary vertices contained in these jets. Thus, it is crucial to study the data vs. simulation distributions of the kinematic variables that are used as inputs for the heavy-flavor tagging algorithms. With the start of LHC Run 3, new track reconstruction methods and changes of the general data-taking conditions have been introduced in the CMS experiment. In this note, a comparison of early Run 3 data vs. simulation distributions for several input variables, tagging discriminants, and other relevant kinematic observables in four different phase space regions that are enriched in b, c, and light (udsg) jets, is presented. The proton-proton collision data recorded by the CMS detector during the early part of the 2022 run, corresponding to an integrated luminosity of 7.65 fb−1, has been used for this study.
Contribution: Wrote code to produce samples, modified code to switch from Run 2 to Run 3 setup, involving new jet collection (PUPPI), and extended input collections (DeepJet). Advised the entire commissioning team on how to efficiently split and produce the samples with CMS tool "CRAB", supported in case of questions or problems with the CMS software + grid resources, and produced samples containing 2022 data myself. Contributed configuration to run the framework at different computing clusters with various priority queues, leading to a net increase of throughput for individual analysers getting the required amount of cores + core hours. Investigated newly added features in a pre-commissioning study to determine their best representation with histograms and checked their validity in an independent cross-check. Parts of my master thesis code are re-used to simplify access and obtain reproducible visualization of tagger input features which requires understanding of their definitions and physical meaning. I kept up with developments of other POGs to include latest recommendations in object selections and ensured the code is in line with official experiment- and era-specific guidelines. I identified a vast amount of (edge) cases and difficult-to-catch technicalities during extensive code review to ensure usability and consistent results across phase spaces and calibrations.
Improving robustness of jet tagging algorithms with adversarial training: exploring the loss surface
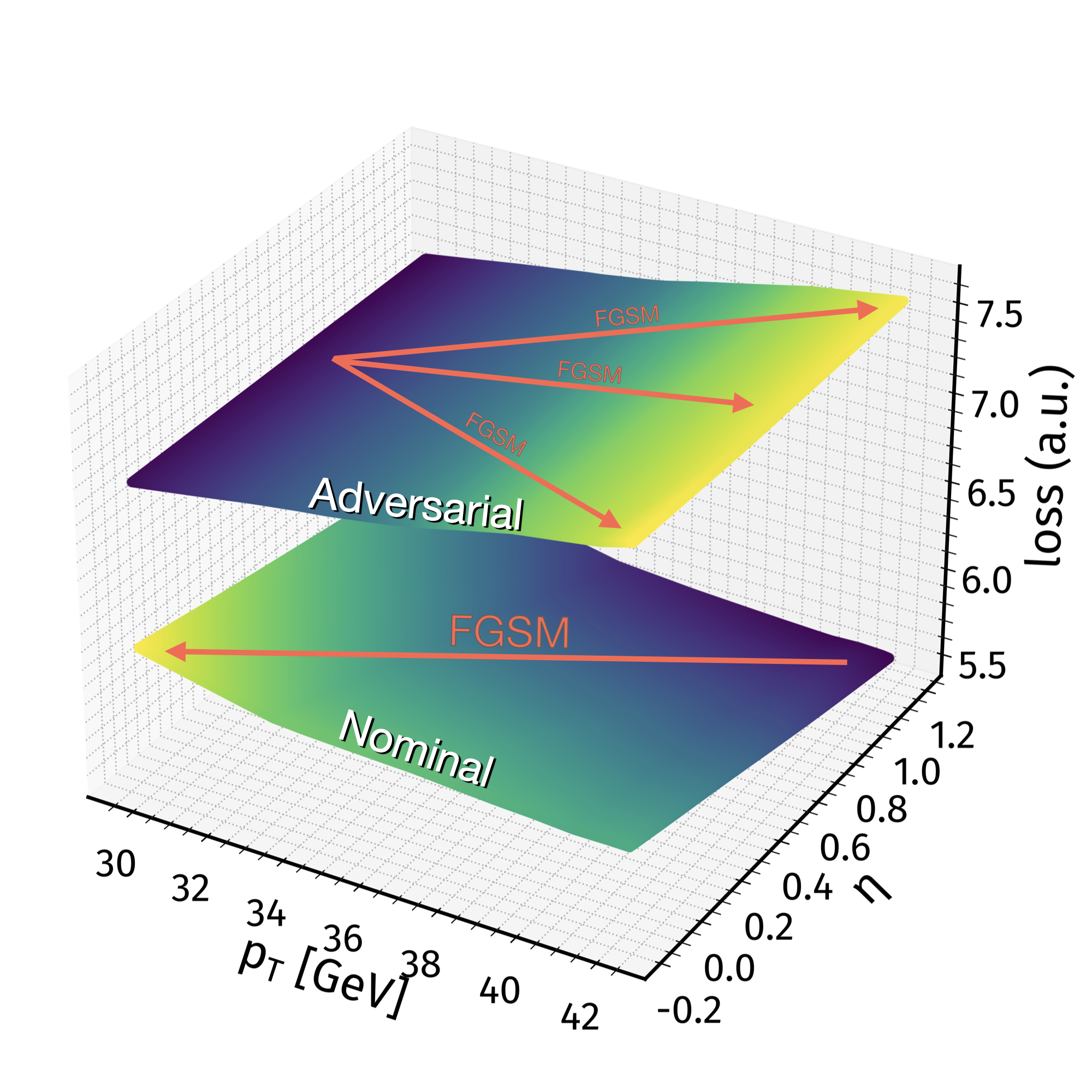 Annika Stein
Annika Stein
- Proceedings of 21th International Workshop on Advanced Computing and Analysis Techniques in Physics Research : AI meets Reality (ACAT 2022), in the Journal Of Physics: Conference Series
arXiv:2303.14511 [hep-ex] | https://doi.org/10.1088/1742-6596/3206/1/012085 | Contribution
25 Mar 2023 (preprint v1) | published 14 Apr 2026 (J. Phys.: Conf. Ser.) 3206 012085.
Abstract
In the field of high-energy physics, deep learning algorithms continue to gain in relevance and provide performance improvements over traditional methods, for example when identifying rare signals or finding complex patterns. From an analyst’s perspective, obtaining highest possible performance is desirable, but recently, some attention has been shifted towards studying robustness of models to investigate how well these perform under slight distortions of input features. Especially for tasks that involve many (low-level) inputs, the application of deep neural networks brings new challenges. In the context of jet flavor tagging, adversarial attacks are used to probe a typical classifier‘s vulnerability and can be understood as a model for systematic uncertainties. A corresponding defense strategy, adversarial training, improves robustness, while maintaining high performance. Investigating the loss surface corresponding to the inputs and models in question reveals geometric interpretations of robustness, taking correlations into account.
Contribution: Main analyzer, developed code, interpreted the results and derived new ideas on top of that, designed the poster (see also previous one here) and then wrote the proceedings. Follow-up of this publication.
Adversarial training for b-tagging algorithms in CMS
CMS Collaboration (Annika Stein)
- Detector Performance Summary, CMS, CERN
CMS DP-2022/049
October 2022
Abstract
Modern neural networks bring considerable performance improvements in various areas of high-energy physics, such as object identification. Flavour-tagging is one example that profits from complex architectures, leveraging information from large numbers of low-level inputs. While such tagging algorithms are evaluated on data and simulation for analysis purposes, training is usually performed with simulated samples only. Differences in performance between these two domains are observed which need to be calibrated against. With a new strategy, called adversarial training, we reduce the observed differences prior to any calibration, and improve robustness of the classifier against injected mis-modelings that mimic systematic uncertainties. In this note, studies on adversarial robustness and agreement between data and simulation are carried out with the DeepJet algorithm, evaluated on Run2 samples. The addition of an adversarial module is envisaged to be included in newly developed tagging algorithms for Run3.
Contribution: Main analyzer, custom dataset production, presentation of final results summarized in the note.
Improving Robustness of Jet Tagging Algorithms with Adversarial Training
Annika Stein, Xavier Coubez, Spandan Mondal, Andrzej Novak, Alexander Schmidt
- Computing and Software for Big Science, 6 (2022) 15
arXiv:2203.13890 [physics.data-an] | https://doi.org/10.1007/s41781-022-00087-1
Code | March 2022 (preprint v1) | published 10 Sep 2022 (Comput Softw Big Sci).
Abstract
Deep learning is a standard tool in the field of high-energy physics, facilitating considerable sensitivity enhancements for numerous analysis strategies. In particular, in identification of physics objects, such as jet flavor tagging, complex neural network architectures play a major role. However, these methods are reliant on accurate simulations. Mismodeling can lead to non-negligible differences in performance in data that need to be measured and calibrated against. We investigate the classifier response to input data with injected mismodelings and probe the vulnerability of flavor tagging algorithms via application of adversarial attacks. Subsequently, we present an adversarial training strategy that mitigates the impact of such simulated attacks and improves the classifier robustness. We examine the relationship between performance and vulnerability and show that this method constitutes a promising approach to reduce the vulnerability to poor modeling.
Contribution: Main analyzer and main / corresponding author. First I performed a similar study for my master thesis, then I rewrote the framework for a new data structure, redid the analysis introducing more validations, interpreted the results. Presented first here.